

The Independent Sentinel #05
The Independent Sentinel #05
Vendedores de humo, SVMs y un dilema Shakesperiano
¡Hola!
Soy Javier Fuentes, CEO de Akoios, gracias por estar leyendo esta nueva edición de The Independent Sentinel, la newsletter que hacemos para compartir con vosotros novedades, noticias y curiosidades sobre Machine Learning y Ciencia de Datos.
Si aún no te has suscrito, puedes hacerlo ahora:
En esta edición hablaremos de los vendedores de humo en el mundo de la Inteligencia Artificial, de las Máquinas de Vectores de Soporte (SVMs) y de la autoría de las obras de Shakespeare.

¡Vamos allá! 🚀
🎼 ¿Quieres banda sonora? ¡Dale al Play!
1. Inteligencia Artificial 🤖
La Inteligencia Artificial, el Hype y los vendedores de humo
De pocos términos se habrá abusado tanto últimamente como de “Inteligencia Artificial”. No paro de ver usos vagos, imprecisos e incluso malintencionados del concepto “Inteligencia Artificial” con el fin último de intentar vender algún producto o servicio “decorado” con este termino de moda.

En esta fantástica presentación, el profesor de Ciencias de la Computación de Princeton Arvind Narayanan habla sobre cómo detectar el “humo” alrededor del concepto Inteligencia Artificial o, como se denomina en inglés, cómo detectar a los vendedores de “Snake Oil”.
Según Narayanan, existe tanto humo alrededor del concepto debido a que la Inteligencia Artificial engloba una amplia variedad de tecnologías y, algunas de ellas, están consiguiendo notorios y relevantes avances.
A modo de ejemplo, el famoso programa AlphaGo desarrollado por Google capaz de ganar a profesionales jugando al “Go”, ha sido considerado como un hito en el desarrollo de la Inteligencia Artificial, ya que aprender a jugar a este juego es un reto que no se esperaba resolver tan pronto.
En su última version, AlphaGo Zero, el programa es capaz de aprender a jugar desde cero jugando millones de partidas contra sí mismo. En este proceso ha conseguido descubrir en un corto periodo de tiempo todo el conocimiento sobre el juego que los humanos han tardado miles de años en recopilar e incluso ha descubierto jugadas aún no conocidas por nosotros 😧
Aprovechando esta confusión de tecnologías que de algún u otro modo se relacionan con la Inteligencia Artificial, algunos avezados vendedores están usando el término para vender mejor alguno de sus productos (¡aunque no tenga relación real con la Inteligencia Artificial!).
Para ejemplificar cómo estructurar las aplicaciones de IA y poder detectar a los vendedores de humo, el autor propone tres categorías:
👉 Percepción: En esta categoría de aplicaciones IA se están realizando avances rápidos y genuinos. Ejemplos:
Identificación de contenidos (Shazam, búsqueda inversa de imágenes)
Reconocimiento Facial
Diagnósticos médicos
Speech to Text
Deepfakes (¡de esto ya hablamos en TIL #4)
👉 Juicio automático: En este ámbito se está mejorando aunque aún se está lejos de la perfección. Esta categoría se centra en la automatización de juicio que haría un humano, por lo que seguramente nunca exista un completo consenso. Ejemplos:
Detección de Spam
Detección de material con Copyright
Evaluación automática de ejercicios o exámenes
Detección de insultos o mensajes de odio
Recomendación de contenidos
👉 Predecir resultados sociales: La fiabilidad de la IA en esta ámbito es, a día de hoy, altamente dudosa. Es aquí dónde están la mayoría de vendedores de humo sobre AI. Los sistemas sociales son tan complejos que es muy difícil poder realizar modelos con resultados precisos. Ejemplos:
Predecir reincidencia criminal
Predecir el resultado de políticas
Predecir idoneidad para un puesto de trabajo
Predecir riesgo terrorista
Predecir situaciones de riesgo para niños
Basándose en comparaciones con estudios como este, Narayanan concluye que, para predecir resultados sociales, la IA no es significativamente mejor que usar un scoring manual usando algunas variables clave.
Así que ya sabéis, ¡mucho cuidado con los vendedores de Snake Oil disfrazando de IA cualquier algoritmo!

Modelos y Algoritmos 💻
Las Máquinas de Vectores de Soporte, llamadas habitualmente SVM (Support Vector Machines) son una de las técnicas más conocidas y utilizadas en Machine Learning para clasificación y detección de patrones.
Su principal ventaja es que son capaces de proporcionar buenos resultados con poco coste computacional.
La idea de las SVMs es simple: trazar una línea o, de forma general un hiperplano, para clasificar y separar una serie de muestras en categorías.
Hiperplanos en 2D y 3D
En este didáctico artículo de Rushikesh Pupale se explica de forma muy clara el funcionamiento básico.
Como bien se detalla, el algoritmo SVM trata de crear una frontera de decisión en la que la separación entre clases o categorías sea la máxima posible.
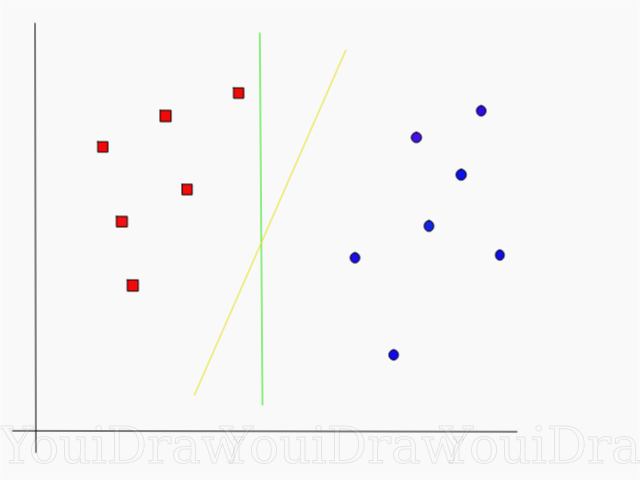
En este ejemplo, la línea en amarillo sería una mejor “frontera” que la línea verde porque deja más distancias entre los grupos. ¿Cómo hace el algoritmo para determinar cuál es mejor?

El mecanismo es el siguiente. SVM encuentra los puntos de cada categoría más próximos a la frontera (¡estos puntos son los llamados vectores de soporte!) y computa la distancia entre ambos. Esta distancia es llamada margen y, lo que hace SVM, es simplemente encontrar el hiperplano que maximiza este margen.
Si quieres saber más sobre SVMs, puedes echar un vistazo a este fantástico tutorial.
Casos de uso ⚙️
Las SVMs se usan de manera generalizada en muchos ámbitos ya que son capaces de clasificar datos desconocidos con precisión. Algunas aplicaciones típicas son:
Detección facial: Las SVMs puede clasificar partes de la imagen entre las categorías cara/no-cara para realizar la detección.
Categorización de textos: Usando SVMs debidamente entrenadas, es posible clasificar de forma automática todo tipo de documentos.
Clasificación de imágenes: De forma general en lo relativo a las imágenes, las SVMs son de gran utilidad para realizar clasificación de imágenes siempre que está debidamente entrenado el modelo.
Biotech: Se están realizando avances interesantísimos en este ámbito relacionados con, por ejemplo, la clasificación de proteínas o clasificación y detección e cánceres. Las SVMs se están usando también para clasificación de genes y pacientes.
Detección de escritura: Otra utilización relevante es el uso de SVMs para reconocer caracteres manuscritos mediante clasificación.
Productivización de modelos 👨🔧
Hace unos días participamos en la XLII edición del Meetup de Machine Learning Spain hablando de cómo superar los problemas para poner en productivo modelos de AI/ML. Al proceso de afrontar estas dificultades para llevar los modelos a producción, lo denominamos internamente como atravesar 💀El Valle de la Muerte 💀.

Comenzando a hablar del Valle de la Muerte
Si quieres saber cómo te podemos ayudar a poner a funcionar en productivo ese modelo increíble que has desarrollado, puedes solicitar un acceso gratuito para probar nuestro producto Titan aquí 👉 https://lnkd.in/gPz-2mJ
2. Historias 📔
¿Escribió Shakespeare todas sus obras?
William Shakespeare nació -supuestamente- el día 26 de Abril de 1564 en Stratford-upon-Avon (llamado normalmente Stratford), en el condado de Warwickshire. Es en esta ciudad dónde se encuentran también sus restos mortales.

La casa donde nació el bueno de Shakespeare
Casi doscientos años después de su muerte en 1616 comenzaron a surgir rumores sobre la autoría de todas sus obras. Para muchos, resultaba inconcebible que alguien de origen rural nacido en un pequeño pueblo, pudiese tener el nivel de educación, sensibilidad y conocimiento de la corte real que Shakespeare demostraba en sus obras.
Los estudiosos de la obra de Shakespeare se dividieron en dos grupos, los Stratfordianos (los partidarios de que el William Shakespeare nacido y fallecido en Stratford fue el verdadero autor de todas las obras) y los Anti-Stratfordianos (los partidarios de la atribución de las obras a otros autores o grupo de autores).
Una de las teorías más conocidas de los Anti-Stratfordianos es la de que William Shakespeare era tan sólo un alias tras los que podían esconderse otros ilustres nombres como Christopher Marlowe (1564-1593), el filósofo y hombre de letras Francis Bacon (1561-1626), Edward de Vere (1550-1604) decimoséptimo conde de Oxford y and William Stanley, sexto conde de Derby.

Las posibles personas detrás de Shakespeare
Aunque las teorías Anti-Stratfordianas han perdido fuerza, aún siguen vigentes y tienen firmes defensores.
No obstante, algunos descubrimientos recientes sobre su obra basados en Machine Learning, puede que vuelvan a reavivar el debate entre Stratfordianos y Anti-Stratfordianos.
En concreto, un paper publicado por Petr Plecháč, de la Academia Checa de Ciencias de Praga, describe cómo utilizando Machine Learning han podido comprobar que la obra Enrique VIII (atribuida inicialmente a Shakespeare), fue en realidad el fruto de la colaboración con unos de los más famosos y prolíficos autores de la época: John Fletcher.

Segunda página de la obra Enrique VIII
Durante gran parte de su vida, Shakespeare fue el dramaturgo principal de la compañía de teatro “The King’s Men”, que solía actuar a las orillas del Támesis en Londres.

The King’s Men
Tras la muerte de Shakespeare en 1616 la compañía nombró como sucesor al mencionado John Fletcher.
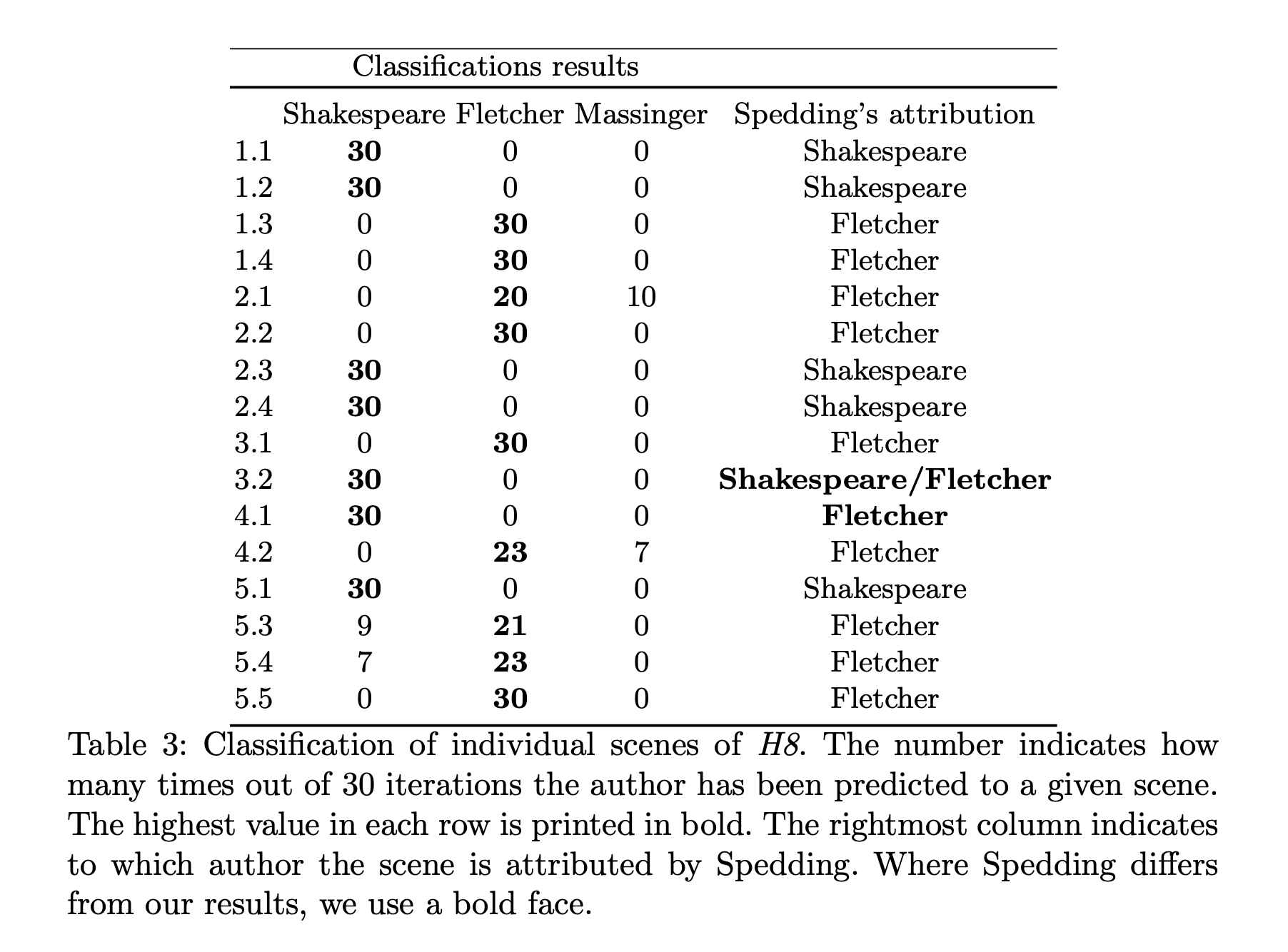
En 1850, el analista literario James Spedding, identificó ciertos patrones que le hicieron pensar que la obra había sido escrita por ambos, o incluso por una tercera persona llamada Philip Massinger. Los patrones que identificó fueron aspectos como que Fletcher usaba a menudo ye en vez de you y ‘em en vez de them, pero nunca logró identificar qué partes específicas de la obra correspondían a cada uno.
Es esto último lo que ha podido descifrar Plecháč en su reciente estudio, al identificar a quién pertenece cada línea de la obra usando un análisis combinado de vocabulario, versificación y técnicas modernas de Machine Learning.
En su primera aproximación, Plecháč ha intentado atribuir los pasajes a cada autor utilizando un clasificador SVM (¡como los que hemos visto anteriormente!) usando como features las 500 frecuencias rítmicas principales y las 500 palabras más usadas.
Para el entrenamiento, Plecháč ha usado las obras de cada uno de los autores:
Shakespeare: The Tragedy of Coriolanus (5 escenas), The Tragedy of Cymbeline (27 escenas), The Winter’s Tale (12 escenas), The Tempest (9 escenas)
Fletcher: Valentinian (21 escenas), Monsieur Thomas (28 escenas), The Woman’s Prize (23 escenas), Bonduca (18 escenas)
Massinger: The Duke of Milan (10 escenas), The Unnatural Combat (11 escenas), The Renegado (25 escenas)
En la siguiente tabla se muestran los resultados y se puede ver cómo de acertado había estado el académico James Spedding en sus predicciones en 1850.
En la siguiente figura se muestra la distribución de autoría de los distintos pasajes de la obra:

Los resultados son muy interesantes, y dan la razón a Spedding en su análisis. El algoritmo es capaz de ir más allá y de identificar cómo la autoría no cambia solo en nuevas escenas, sino que lo hace hacia el fin de las anteriores. Como ejemplo, en la escena 2 del acto 3 (3.2) parece que hay autoría conjunta después de la línea 2081 y que Shakespeare toma el control sobre la línea 2200 (ambas líneas las podéis ver identificadas en la figura de arriba).
Este es sin duda un caso de uso maravilloso en el que se puede ver cómo estas nuevas técnicas nos pueden ayudar a indagar más en nuestro pasado literario.
Quién sabe, tal vez el Machine Learning sea capaz de zanjar para siempre el enfrentamiento entre Stratfordianos y Anti-Stratfordianos. Time will tell!

¡Gracias por leer hasta aquí! ¡Hasta pronto!
¿Te gusta The Independent Sentinel? ¡Ayúdanos a que nos conozcan compartiendo nuestras publicaciones en RRSS!
¿Quieres leer más? Puedes ver las ediciones anteriores aquí:
👉 Si quieres conocer mejor cómo funciona nuestra tecnología, no te pierdas nuestra serie de tutoriales publicados en Medium.